
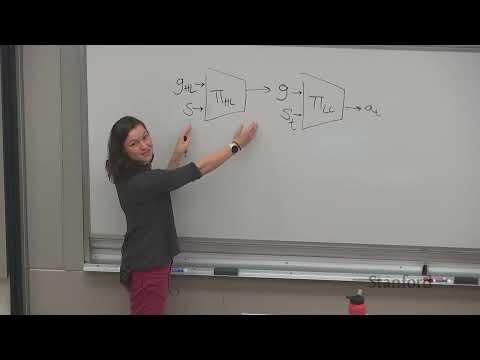
1. Course Details
This is the 15th lecture of Stanford University's CS224R Deep Reinforcement Learning course. Building on prior topics of multi-task learning and meta-reinforcement learning, this lecture introduces hierarchical learning as a framework to solve complex long-horizon tasks that require sequencing multiple subtasks.The lecture covers the fundamental motivation for hierarchical approaches, the core two-level policy architecture, three critical design choices for building practical hierarchical systems, and detailed examples of state-of-the-art hierarchical imitation learning systems for robotics. It concludes with a discussion of hierarchical reinforcement learning and open research directions in the field.2. Key Learning Objectives
By the end of this lecture, students will be able to:-
Explain the core challenges of long-horizon tasks that make them difficult for standard flat policies
-
Describe the basic hierarchical policy architecture and its key advantages over flat policies
-
Evaluate the tradeoffs between different goal representations including language, images, and structured states
-
Design effective supervision strategies for hierarchical systems to avoid dangerous module mismatch
-
Implement practical hierarchical imitation learning systems using both language and image subgoals
-
Compare hierarchical approaches to alternative methods like chain-of-thought reasoning
-
Identify the current limitations of hierarchical reinforcement learning and promising future research directions
3. Memorable Quotes
-
"Long-horizon tasks are some of the hardest problems for AI systems to solve, because they require navigating vast state spaces, recovering from mistakes, and avoiding getting stuck in loops of non-progress."
-
"The core idea behind hierarchy is simple: break a single overwhelming long task into smaller, manageable subtasks, then compose them with a higher-level controller."
-
"Intermediate supervision is the single biggest benefit of hierarchical approaches—without it, sparse rewards for long tasks make learning nearly impossible."
-
"The biggest pitfall of modular hierarchical systems is the mismatch between levels: a low-level policy trained in isolation will fail when called from states the high-level policy actually produces."
-
"Errors in estimating when a subtask is complete are far more fatal than frequent high-level re-planning, which is why almost all practical systems use fixed-frequency goal updates."
4. Detailed Lecture Notes
4.1 The Challenge of Long-Horizon Tasks
Long-horizon tasks are complex activities that require multiple sequential steps to complete, often with interdependent subtasks. Examples include cooking a meal, debugging a neural network, driving across the country, or drafting a legal brief.These tasks present three unique challenges for AI systems:-
Vast state spaces: The agent must make appropriate decisions across thousands or millions of unique states encountered during the task
-
Error recovery: Mistakes are inevitable, and the agent must be able to recognize and correct them rather than failing catastrophically
-
Progress stagnation: Agents easily get stuck in loops of repetitive behavior that makes no forward progress toward the goal
4.2 Core Hierarchical Policy Architecture
Hierarchical learning addresses these challenges by decomposing the problem into multiple levels of abstraction. The standard two-level architecture consists of two separate policies operating at different timescales:-
Low-level policy (π_LL): Operates at the original action frequency (e.g., 20 hertz for robot motors, word-by-word for language models). It takes the current state and an intermediate subgoal as input and outputs primitive actions to execute that subgoal.
-
High-level policy (π_HL): Operates at a much coarser timescale. It takes the current state and the overall high-level task as input and outputs a sequence of intermediate subgoals for the low-level policy to accomplish.
Execution Workflow
-
The high-level policy observes the initial state and plans the first intermediate subgoal
-
The low-level policy repeatedly executes actions to achieve the current subgoal
-
After a predetermined period or when the subgoal is complete, the high-level policy observes the new state and plans the next subgoal
-
This process repeats until the overall task is completed
Alternative: Chain-of-Thought Reasoning
An intermediate approach that retains many benefits of hierarchy without separate policies is chain-of-thought reasoning. In this approach, a single policy first outputs an intermediate subgoal or reasoning step, then outputs the corresponding low-level action.-
Advantages: Enables knowledge sharing between the reasoning and execution components
-
Disadvantages: No computational efficiency benefit, as reasoning must be performed at every timestep
4.3 Three Critical Design Choices
Building an effective hierarchical system requires making three fundamental design decisions that will largely determine its performance.4.3.1 Goal Representation
The choice of how to represent intermediate subgoals is highly domain-dependent and must balance three competing requirements:-
Expressiveness: The ability to describe all necessary subtasks for the domain
-
Structure: Similar goals should have similar representations to enable generalization
-
Appropriate abstraction: Goals should be neither too fine-grained (defeating the purpose of hierarchy) nor too coarse-grained (failing to decompose the problem)
-
Natural language: The most general and expressive representation, ideal for tasks like cooking or cleaning. It is easy for humans to annotate and understand but can suffer from ambiguity.
-
Goal images: Excellent for visual robotic tasks. They eliminate the need for language annotation and can leverage vast amounts of unlabeled video data for pre-training.
-
Structured representations: GPS coordinates, bounding boxes, or joint angles for navigation and control tasks. These have strong inherent structure that makes learning easier.
-
Latent representations: Learned neural activations that require no human annotation but are completely uninterpretable.
4.3.2 Supervision for Each Level
The most common failure mode for hierarchical systems is module mismatch: when the low-level policy is trained on states that the high-level policy never actually produces during deployment.To avoid this:-
Pre-train the low-level policy on a wide distribution of states and goals to ensure it is robust
-
Adapt the high-level policy to the actual capabilities and failure modes of the low-level policy
-
Jointly fine-tune both policies end-to-end whenever possible to align their behaviors
4.3.3 When to Switch Goals
There are two basic strategies for deciding when to request a new subgoal from the high-level policy:-
Completion-based switching: Request a new goal only when the low-level policy indicates it has completed the current one
-
Advantages: Maximum computational efficiency
-
Disadvantages: Extremely difficult to accurately estimate task completion; cannot handle errors that require revisiting previous subtasks; failures lead to permanent stagnation
-
-
Fixed-frequency switching: Request a new goal at regular, predetermined intervals
-
Advantages: Simple, robust, and automatically recovers from errors by re-planning frequently
-
Disadvantages: Introduces small delays between subtask completion and new goal assignment; higher computational cost
-
4.4 Practical Hierarchical Imitation Learning Systems
Most successful hierarchical systems deployed today use imitation learning rather than reinforcement learning, as RL remains unstable and sample-inefficient for long-horizon tasks.4.4.1 Language Subgoal Systems
These systems use natural language as the intermediate goal representation:-
Data collection: Long-horizon demonstrations are segmented and annotated with language labels describing each subtask. This can be done either during data collection or post-hoc.
-
Architecture: A high-level policy takes RGB images as input and predicts language subgoals. A low-level policy takes RGB images, joint angles, and the language subgoal as input and predicts joint motor commands.
-
Training process:
-
Pre-train both policies offline on the annotated demonstration data
-
Freeze the low-level policy
-
Fine-tune the high-level policy using DAgger with human language interventions
-
-
Results: Hierarchical systems achieve a 34% improvement in task progress compared to equivalent flat policies and can complete complex tasks like putting three objects into a sealed bag or cleaning an entire bedroom.
4.4.2 Image Subgoal Systems
These systems use generated images as the intermediate goal representation:-
Data collection: Only raw video demonstrations are required, with no language annotation.
-
Architecture: A high-level diffusion model takes the current image and high-level task as input and generates a subgoal image representing what the scene should look like several seconds in the future. A goal-conditioned low-level policy takes the current image and subgoal image as input and predicts actions.
-
Key advantages:
-
Can handle novel objects that have no standard language name
-
Can leverage massive amounts of unlabeled human video data for pre-training
-
Adding human video data to the training set significantly improves generalization performance
-
4.5 Hierarchical Reinforcement Learning & Open Directions
While hierarchical imitation learning has seen significant recent success, hierarchical reinforcement learning remains less mature but offers the potential for much higher reliability and performance.Current approaches typically use:-
A goal-conditioned low-level policy trained to reach arbitrary states
-
A high-level policy that outputs goal states or language subgoals
-
Hindsight relabeling to make efficient use of off-policy data for training the high-level policy
-
Unsupervised skill discovery: Can we automatically discover useful reusable skills without any human supervision or annotation?
-
Scalable hierarchical RL: How can we effectively fine-tune large pre-trained hierarchical imitation learning systems with reinforcement learning?
-
Multi-level hierarchy: Can we learn deep hierarchies with more than two levels of abstraction automatically?
-
These are my structured study notes and in-depth interpretations compiled by watching the open course. I hope this knowledge framework helps you thoroughly master the content of this subject. Wish you continuous academic progress and great achievements in your studies.








